团队经过讨论,决定通过使用Python的splinter模块,打开chrome浏览器模拟用户进行登录和微博搜索等操作。
除了使用网络爬虫爬去相关数据外,我们还在数据入库前对数据进行了统一的格式化清洗工作。
.jpg)
我们的挖掘与可视化所使用的数据集来源广泛:新浪微博核心数据新浪微博话题榜榜单数据、CSM全国测量仪数据、百度风云榜榜单数据、百度贴吧会员数、百度贴吧帖子数百度高级搜索数据集等。
.jpg)
为了达到从海量微博用户数据中提取出和电视节目热点相关的信息,团队决定采用多种方法融合的社交网络算法以及关联分析方法对我们的数据进行分析与挖掘。具体方法包括中文分词、语义分析、性格筛选等。
.jpg)
我们不仅实现了散点图、条形图、折线图、扇形图等多种图表格式,同时还具有绘制网络拓扑图、二维矩阵、联动数据图表、LBS数据的能力。
元素拖拉拽、图表重计算、图表形式转换、可视化结果保存等也已实现。
.jpg)




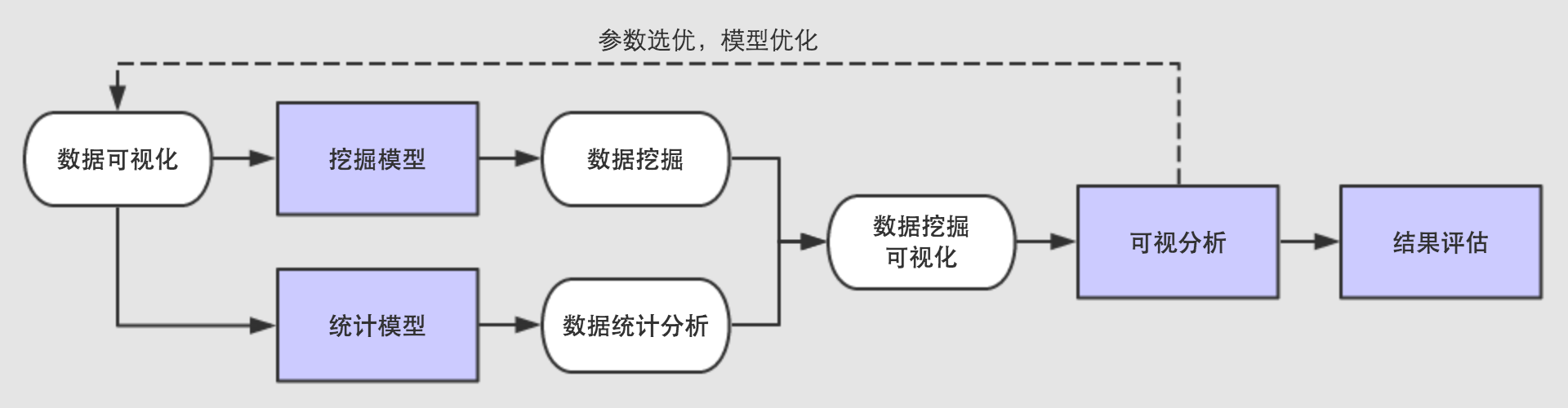
大数据时代,通过数据挖掘可以对数据库中的大量数据进行抽取、转换、分析和其他模型化处理,从而提取辅助商业决策的关键性信息。本系统以《爸爸去哪儿》电视节目为分析背景,是Data.BIT参赛队根据第三届中国软件杯大赛“数据挖掘可视化”赛题准备的一套从数据采集到数据可视化一系列的全套数据处理平台,通过融合强大的数据可视化技术,让数据挖掘过程门槛大大降低,任何人都可以读懂挖掘的全过程。