Let's GAN
黯晓 2018.12
简单聊聊人脸识别
人脸
-
Detect/检测
-
Recognize/辨别
-
Generate/生成
-
Showcase
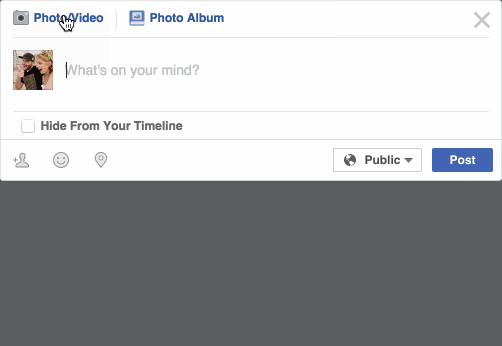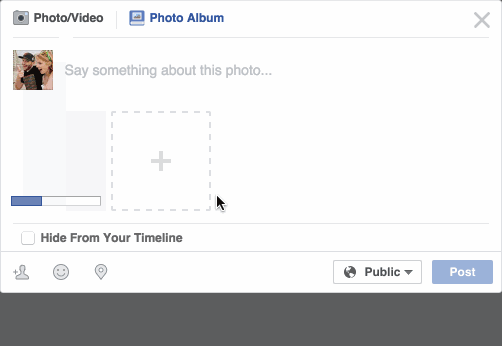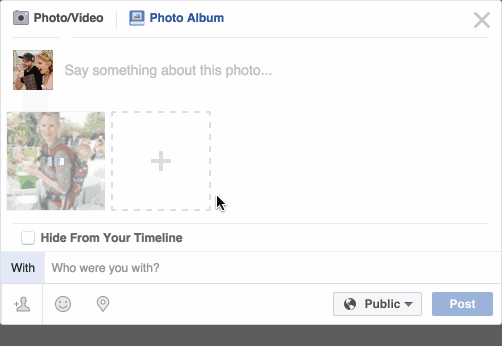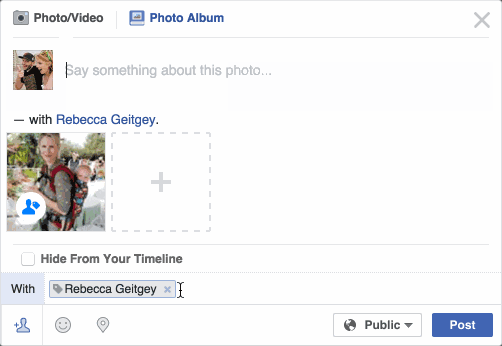
Facebook 发送状态
Facebook会自动识别到你的朋友,并标注出来,成功率高达98%*

如何区分威尔·法瑞尔(Will Ferrell,著名演员)和查德·史密斯(Chad Smith,著名摇滚音乐家)?
1. Detect/检测

1.1 图片数据化
定向梯度直方图 / HOG / Histograms of Oriented Gradients for Human Detection



Step 1
Step 2
Step 3
1.2 特征提取
定向梯度直方图 / HOG / Histograms of Oriented Gradients for Human Detection
Step 4
Step 5
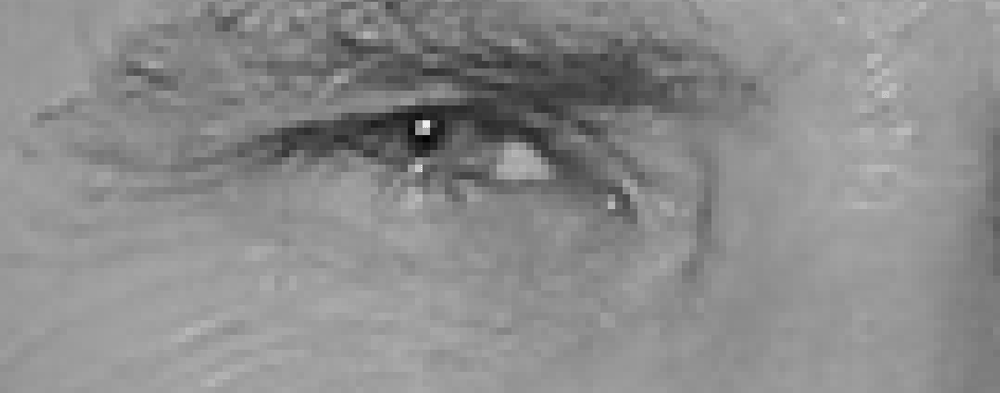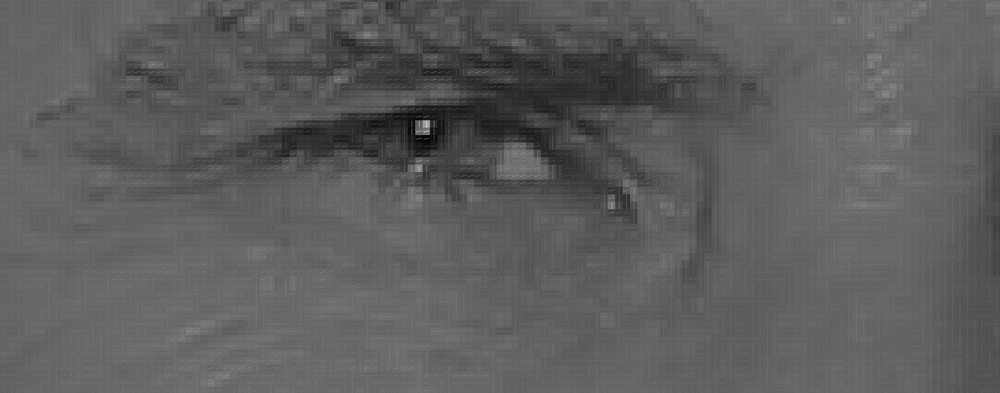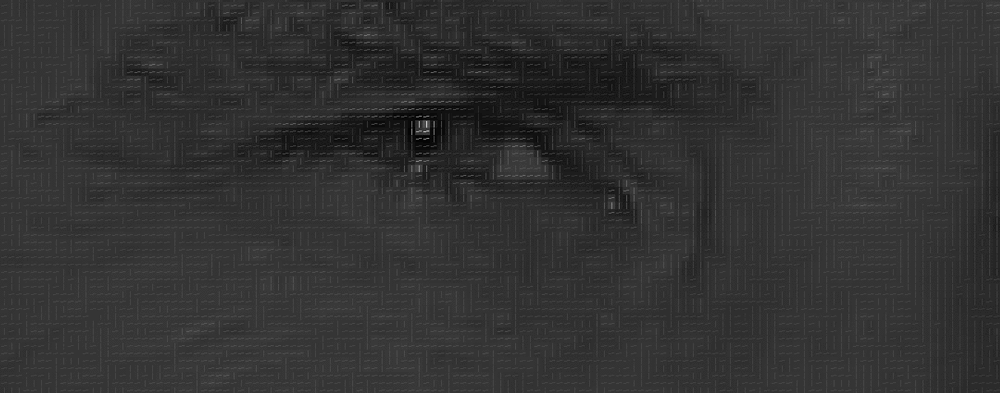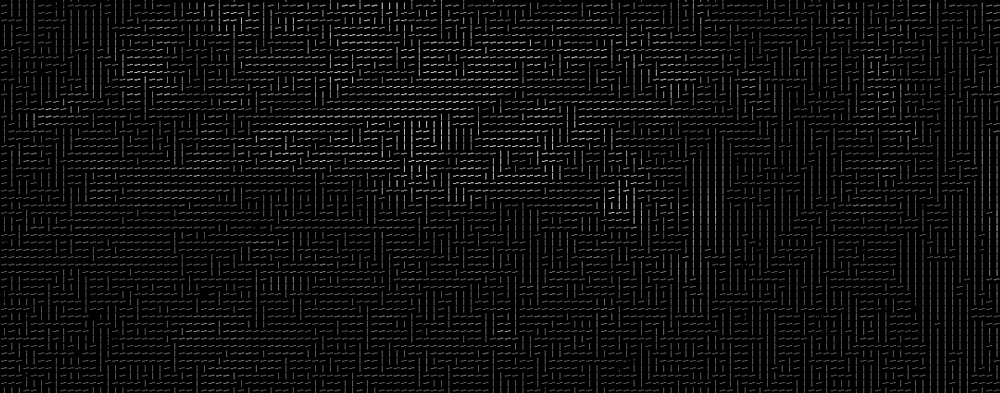

1.3 样本匹配


DONE
2. Recognize/辨别

如何做到同一人脸不同姿态、不同人脸间都要可识别?

2.1 estimation and Transformation
ERT算法 / Ensemble of Regression Trees

2.1.1 face landmark estimation
ERT算法 / Ensemble of Regression Trees
找到 68 个人脸上普遍存在的特定点(称为特征点, landmarks)——包括下巴的顶部、每只眼睛的外部轮廓、每条眉毛的内部轮廓等。然后训练一个机器学习算法,让它能够在任何脸部找到这 68 个特定的点:


Step 1
Step 2
2.1.2 face Transformed
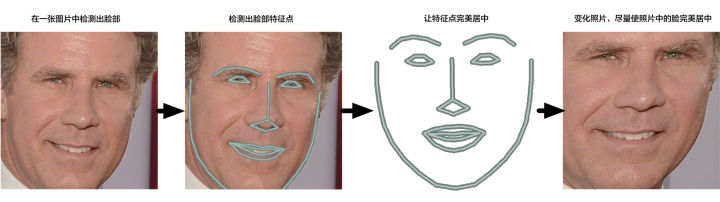
2.2 面部编码
2.2 面部编码
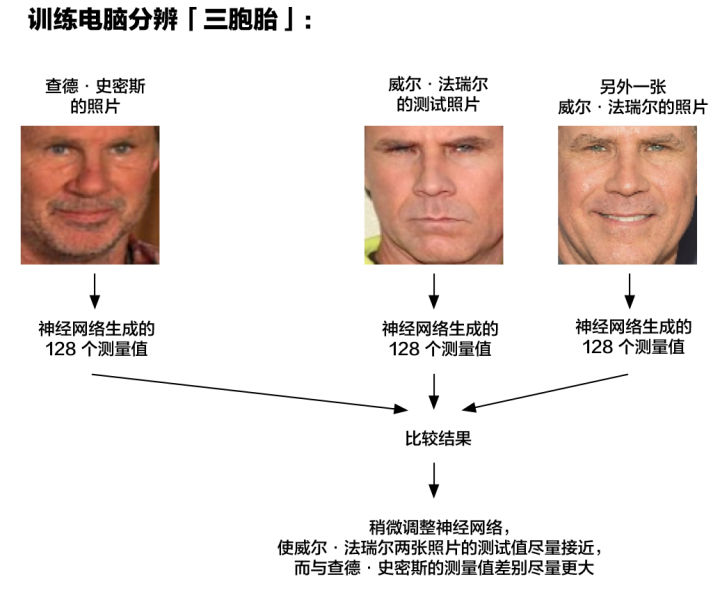
深度神经网络——让计算机自己找到可区分面部的测量值
128个测量值称为一个嵌入(embedding),通过训练卷积神经网络来输出脸部嵌入的过程,需要大量的数据和强大的计算能力。
耗时巨大,但一旦网络完成,即使它从来没有见过这些面孔,它也可以生成这张面孔的测量值。
2.2 面部编码
这 128 个数字到底测量了脸部的哪些部分?不知道!
但是这对我们并不重要。我们关心的是,当看到同一个人两张不同的图片时,我们的网络需要能得到几乎相同的数值。

2.3 这张脸是谁的 / 分类器
SVM / 支持向量机 / Support Vector Machine

2.4 结果
3. Generate/生成
GAN / TBD
生成让人信服且从未见过的人脸?生成 everything...
4. Showcase
import * as cocoSsd from "@tensorflow-models/coco-ssd";
const image = document.getElementById("image")
cocoSsd.load()
.then(model => model.detect(image))
.then(predictions => console.log(predictions))物体检测 Tensorflow.js + Canvas / 实例分割...
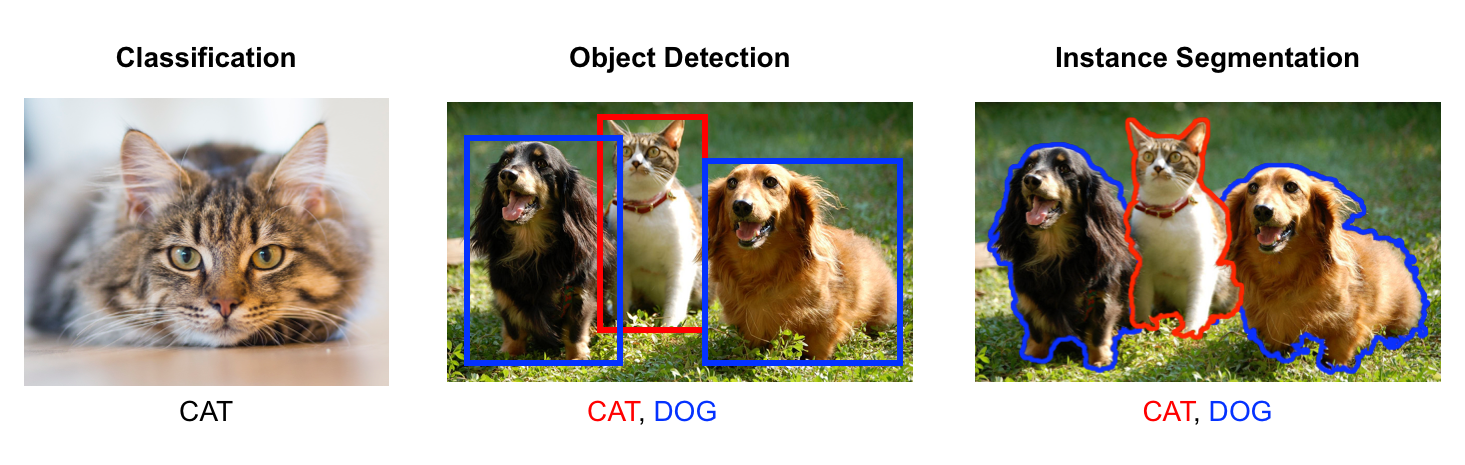
4. Showcase / 1
4. Showcase / 2
实时物体检测
// Web 摄像头
const video = document.getElementById("video")
navigator.mediaDevices
.getUserMedia({
audio: false,
video: {
facingMode: "user",
width: 600,
height: 500
}
})
.then(stream => {
video.srcObject = stream
video.onloadedmetadata = () => {
video.play()
}
})
// 逐帧检测
function detectFrame() {
model.detect(video).then(predictions => {
renderOurPredictions(predictions)
requestAnimationFrame(detectFrame)
})
}4. Showcase / 2
实时物体检测
4. Showcase / 3
生成动漫头像





4. Showcase / 4
4. Showcase / 5
4. SHowcase
应用场景....太多了
抖音视频识别人脸加挂饰
支付宝人脸免密登陆
......


5. take away
所以我们来回顾一下如何进行人脸识别
- 使用 HOG 算法给图片编码,以创建图片的简化数字版本。
- 使用这个简化的图像,找到其中最像通用 HOG 面部编码的部分(或者压根就没有)。
- 通过找到脸上的主要特征点,找出脸部的姿势。
- 定位这些特征点,利用它们把图像扭曲,使眼睛和嘴巴等关键部位居中。
- 把居中的面部图像放入神经网络(当然要有训练过程),找到特征测量值(landmarks)并保存。
- 建立分类器,对不同人脸进行分类与匹配数据存储。
- 对比已经测量过的所有脸部,找出哪个测量值和我们提供的最接近(概率)。
- 这就是你要找的人。
对于产业来说
人脸识别不仅技术完备,而且应用场景非常丰富。
对于 Web 开发者来说
Tensorflow.js 是一个非常好的应用工具库。
6. Reference / 去马赛克相关学术资料
[1] I. Goodfellow. Nips 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016.
[2] A. B. L. Larsen, S. K. Sønderby, Generating Faces with Torch. Torch | Generating Faces with Torch
[3] A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther. Autoencoding beyond pixels using a
learned similarity metric. In ICML, pages 1558–1566, 2016.
[4] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi. Photo-realistic single image super-resolution using a generative adversarial network. arXiv:1609.04802, 2016.
[5] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
[6] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015.
[7] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Learning deep features for discriminative localization. arXiv preprint arXiv:1512.04150, 2015.
[8] He, D., Xia, Y., Qin, T., Wang, L., Yu, N., Liu, T.-Y., and Ma, W.-Y. (2016a). Dual learning for machine translation. In the Annual Conference on Neural Information Processing Systems (NIPS), 2016.
[9] Tie-Yan Liu, Dual Learning: Pushing the New Frontier of Artificial Intelligence, MIFS 2016
[10] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networkss. arXiv preprint arXiv:1703.10593, 2017.
[11] T. Kim, M. Cha, H. Kim, J. Lee, and J. Kim. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. ArXiv e-prints, Mar. 2017.
[12] Z. Yi, H. Zhang, P. T. Gong, et al. DualGAN: Unsupervised dual learning for image-to-image translation. arXiv preprint arXiv:1704.02510, 2017.
[13] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems (NIPS), 2016.
[14] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. arXiv preprint arXiv:1703.00848, 2017.
[15] Dong, H., Neekhara, P., Wu, C., Guo, Y.: Unsupervised image-to-image translation with generative adversarial networks. arXiv preprint arXiv:1701.02676, 2017.
6. REFERENCE / 参考资料
- https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
- http://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
- http://www.csc.kth.se/~vahidk/papers/KazemiCVPR14.pdf
- https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
- https://cmusatyalab.github.io/openface/
- http://www.iangoodfellow.com/slides/2016-12-04-NIPS.pdf
- https://alantian.net/ganshowcase/
- https://medium.com/@bourdakos1/tensorflow-js-real-time-object-detection-in-10-lines-of-code-baf15dfb95b2
- https://hackernoon.com/tensorflow-js-real-time-object-detection-in-10-lines-of-code-baf15dfb95b2
- https://zhuanlan.zhihu.com/p/27199954
- https://zhuanlan.zhihu.com/p/24567586